
ArXiv
Preprint
Source Code
Github

Data
Generation
Model Weights
How Do Transformers Reason About Variables In-Context?
Much of the performance of language models (LMs) can be attributed to the power of token embeddings; prior work has shown that token embeddings can pre-encode rich semantic, syntactic, and numeric structure. However, the hallmark of abstract reasoning is the ability to work with words and symbols whose meaning is unknown ahead of time.
In this paper, we design an in-context learning setting to study the computational strategies that transformers develop to solve abstract arithmetic tasks. What makes our setting unique is that each token is a variable that can represent any algebraic element, and tokens acquire meaning only through their interactions within a sequence. In contrast to the geometric representations learned for numeric reasoning seen in prior work (where token meanings are fixed), we find that models develop symbolic reasoning mechanisms based on sparse relational patterns. Our findings suggest that the kinds of reasoning strategies learned by transformers are dependent on the task structure.
The Task: In-Context Algebra
We train transformers to solve arithmetic problems sampled from a mixture of finite groups (like cyclic and dihedral groups). Each task sequence presents several examples of products between elements in a group with the goal that models will learn to predict the outcome of unseen group products. However, key challenge is that each token is a variable whose meaning changes between sequences. For example, the symbol "g" might represent the identity in one sequence but a 90-degree rotation in another. Models can infer what each symbol means only from how it interacts with other symbols in-context. You can try to solve some example in-context algebra sequences for yourself below.
Try It Yourself
Can you predict the answer? Look at the sequence of facts below and try to figure out what comes next:
Sequence Generation
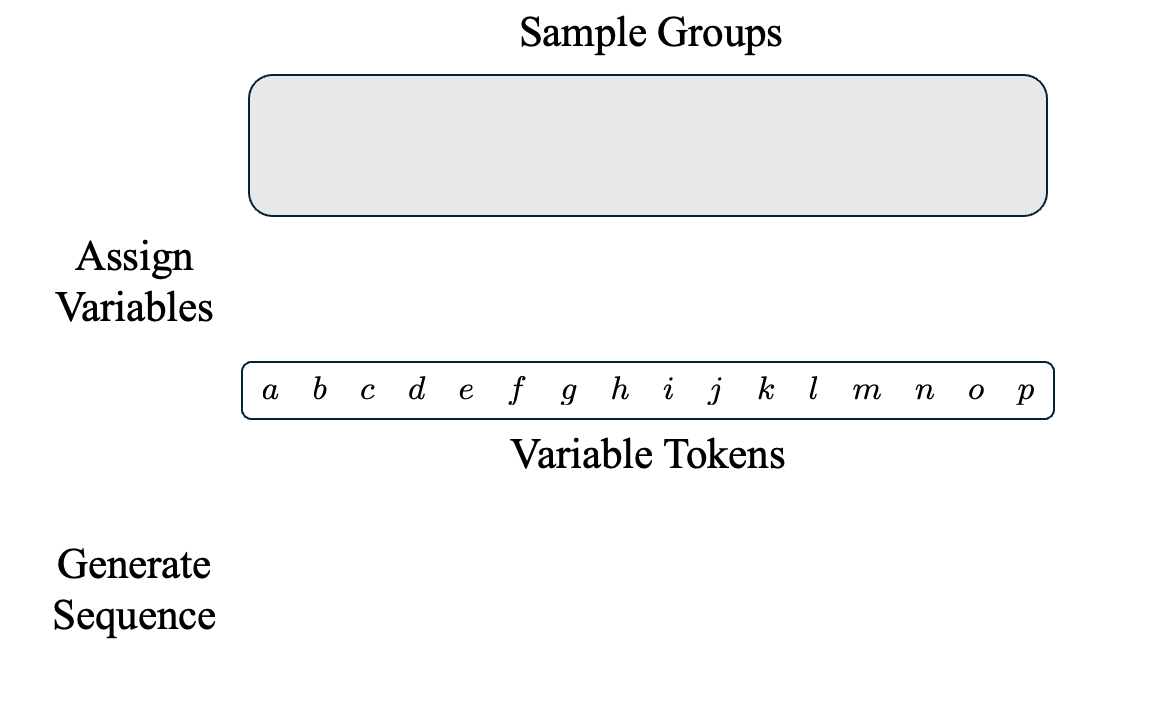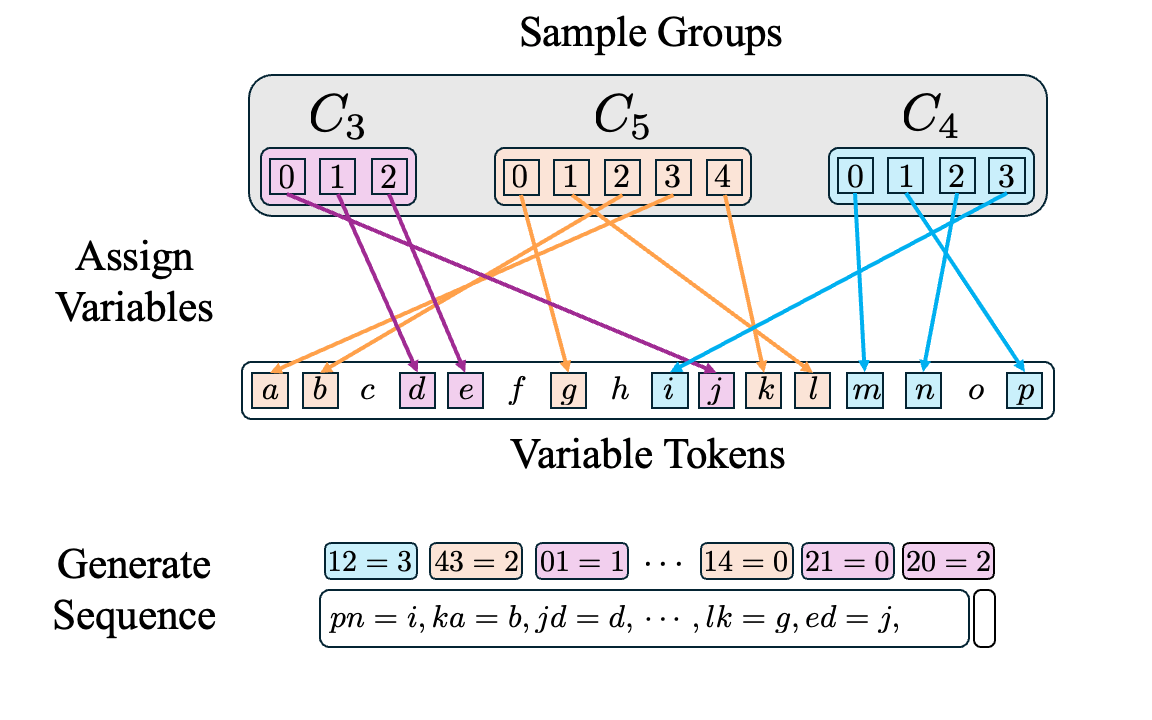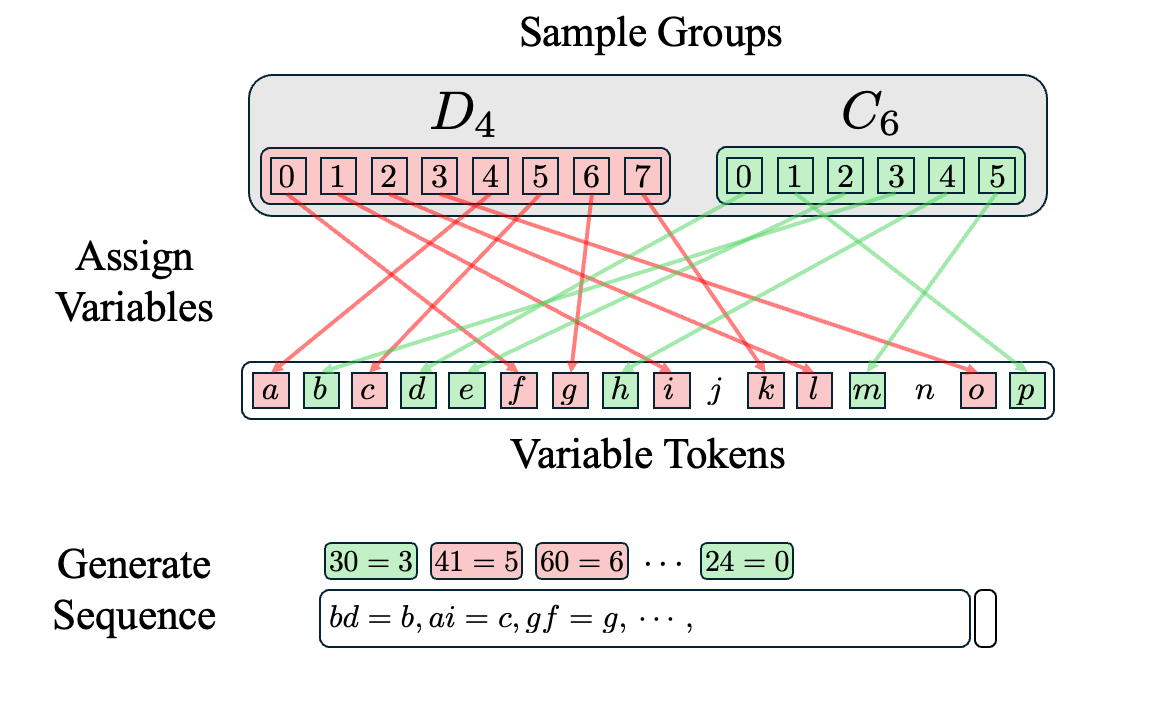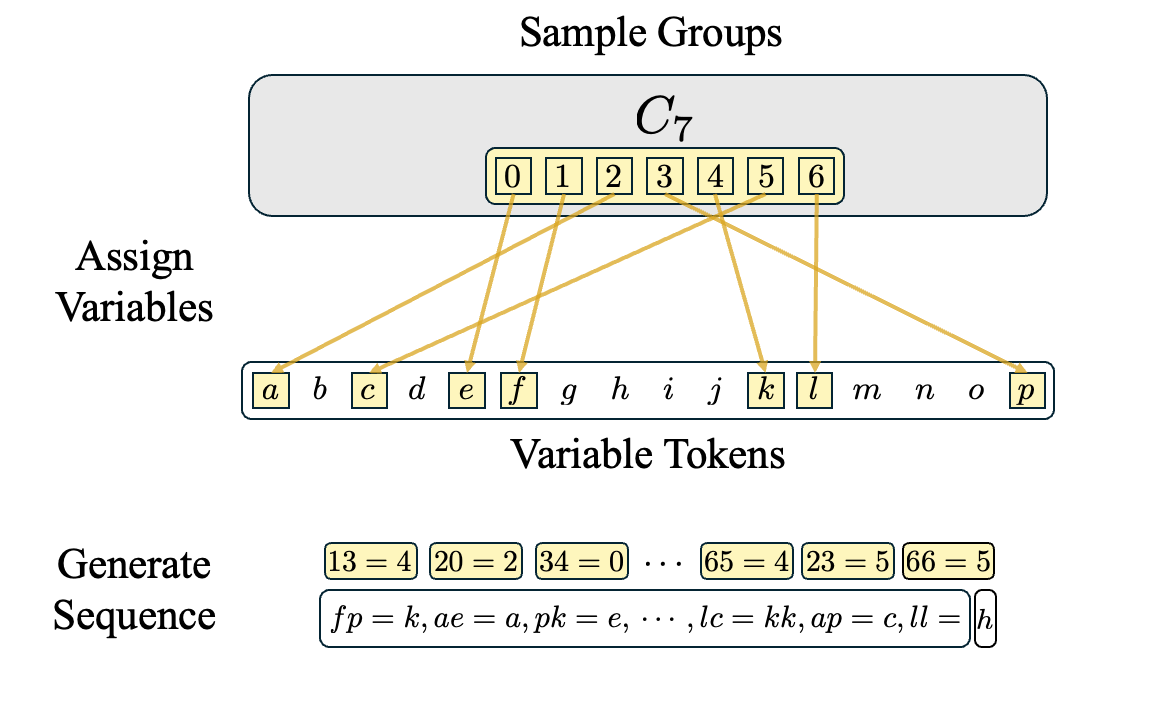
We generate in-context algebra sequences in three steps:
- Sample a set of groups with total order less than or equal to the number of variable tokens.
- Assign a variable token to each group element using a random one-to-one mapping.
- Sample facts from the randomly sampled groups, convert facts into variable statements, and concatenate them together into a sequence.
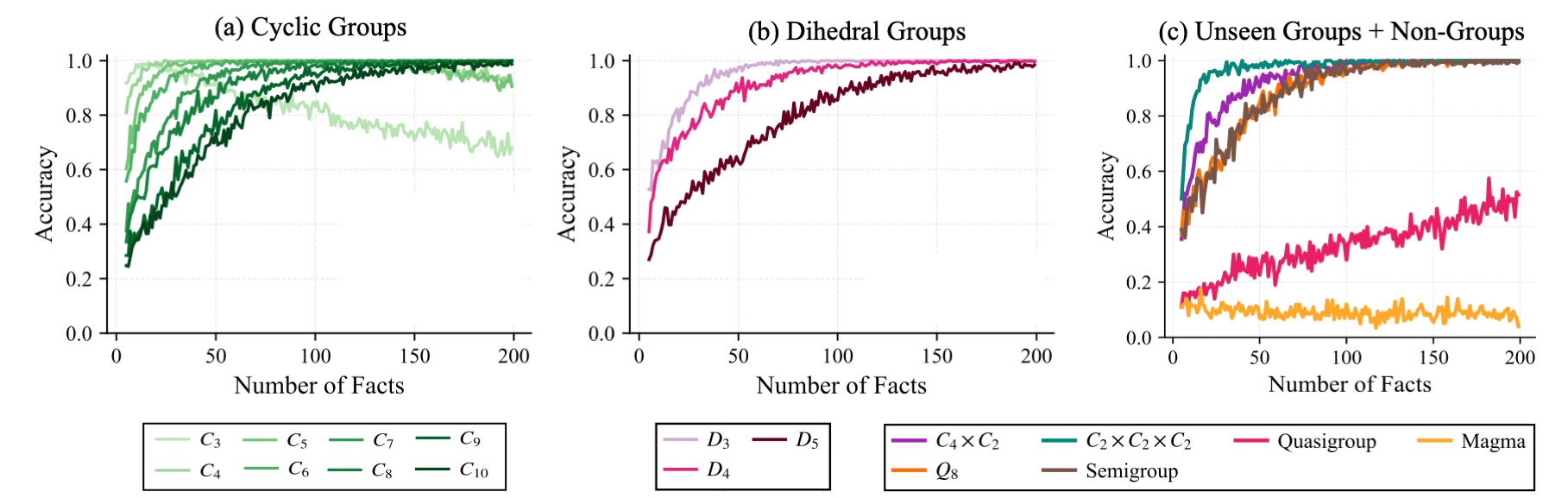
Can Transformers Learn This Task?
Models achieve near-perfect hold-out accuracy for in-distribution groups: (a) cyclic groups and (b) dihedral groups. In general, hold-out performance improves as more facts are given as context to the model. More surprising is the model's generalization to (c) unseen groups. Models also perform well on semigroups, but worse on quasigroups and collapse on magmas (also shown in (c)).
Hypothesizing Model Mechanisms
As you probably saw when trying to solve different sequences, it's possible that multiple algorithms could theoretically produce correct predictions. This can make it challenging to identify which mechanisms the model actually implements. To disambiguate between potential mechanisms, we design five targeted data distributions to test specific algorithms that can solve algebra sequences when a corresponding set of facts is present in the context: Verbatim Copying, Commutative Copying, Identity Element Recognition, Closure-Based Cancellation, and Associative Composition.
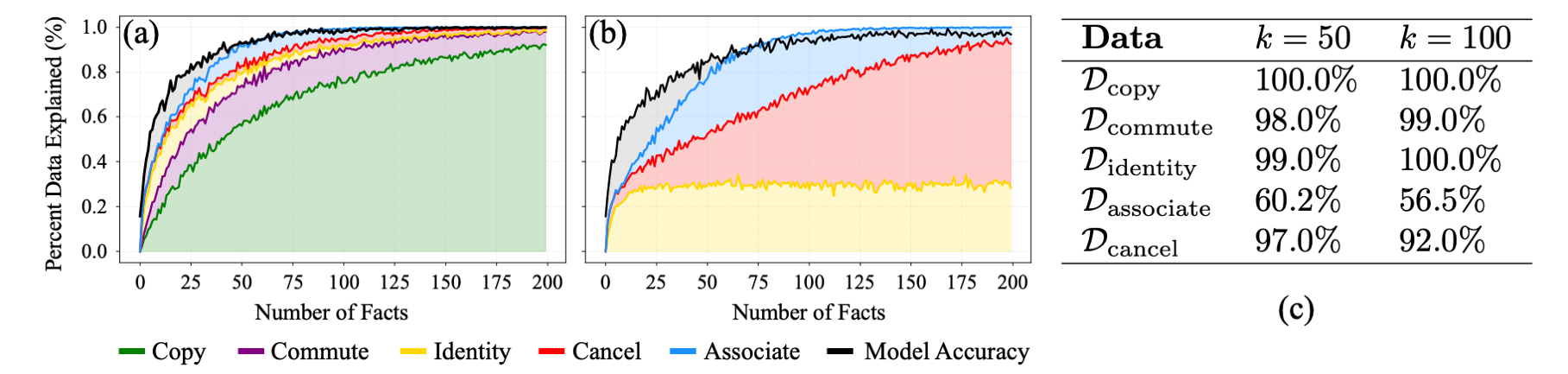
We measure the percentage of (a) training sequences and (b) hold-out sequences that these algorithms can theoretically solve. We find that they can solve 90.4% of training sequences (AUC) and 84.7% of hold-out sequences, within 2-3% of the model's empirical performance (shown in black). The model shows very good empirical performance on four of the five targeted data distributions, with associativity being more challenging.
Verifying Mechanisms
Based on the results above, we investigate how the model implements the strategies with stronger empirical evidence: Verbatim Copying, Commutative Copying, Identity Element Recognition, and Closure-Based Cancellation. The results in this section are based on a single representative model, though we see similar results across training runs.
Copying and Commutative Copying
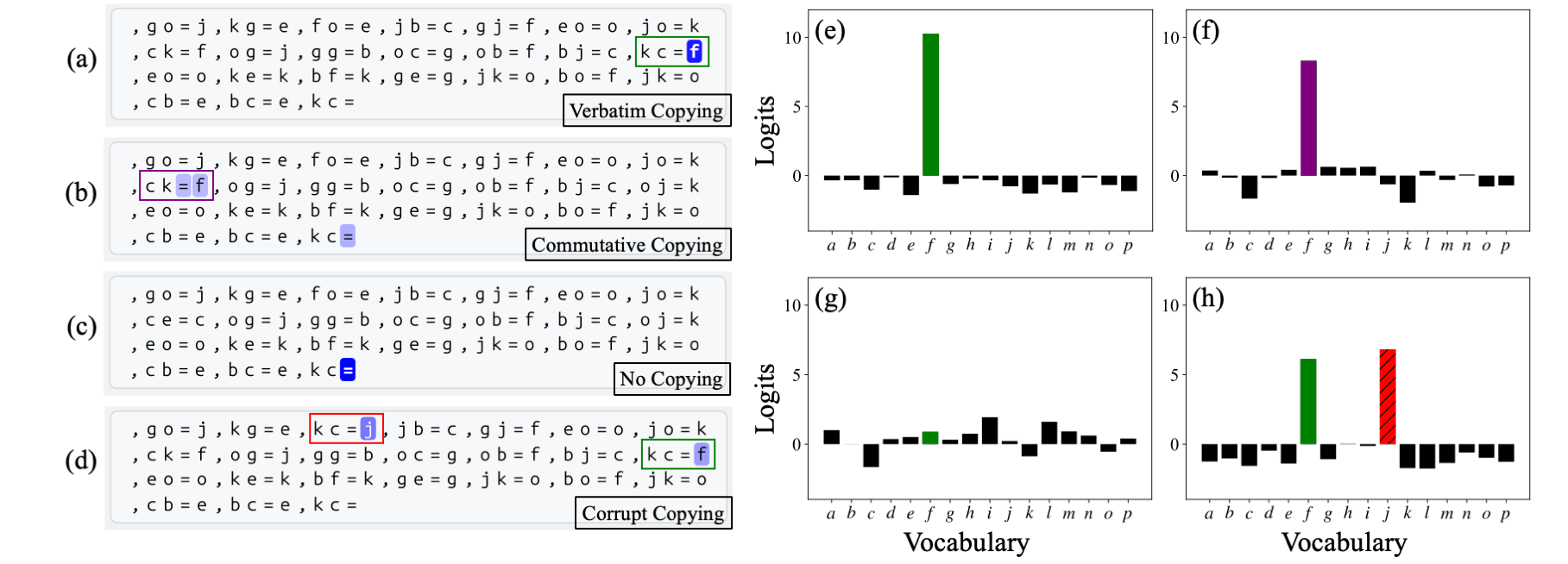
We find a single attention head is primarily responsible for copying answers from context, similar to the induction heads from (Olsson et al., 2022) or n-gram heads seen in (Akyürek et al., 2024). This head performs both verbatim copying (when an exact duplicate fact exists) and commutative copying (when a commutative pair exists, e.g., copying "ba = c" when the query is "ab ="). However, because not all products are commutative (in dihedral groups), this copying heuristic can't always solve a sequence, and additional mechanisms described below refine the prediction.
Identity Element Recognition
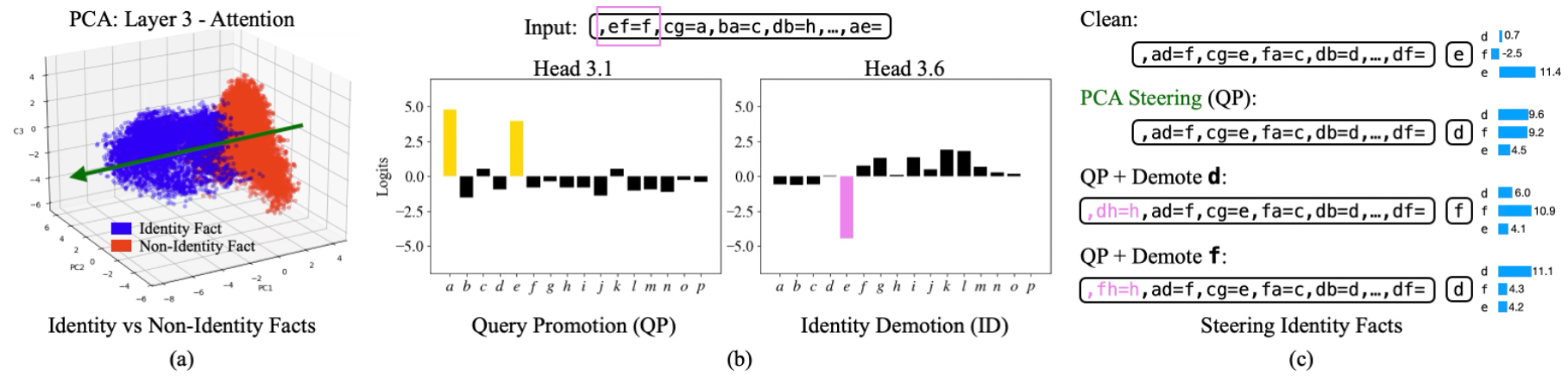
The model learns to represent facts with identity elements differently from other facts, which can be seen clearly when using PCA on the model's hidden states. The model solves identity facts from the interaction of two complementary mechanisms: query promotion which promotes both variables in the question as potential answers, and identity demotion which attends to and suppresses the known identity element. When both activate simultaneously, the non-identity token is correctly selected.
Closure-Based Cancellation
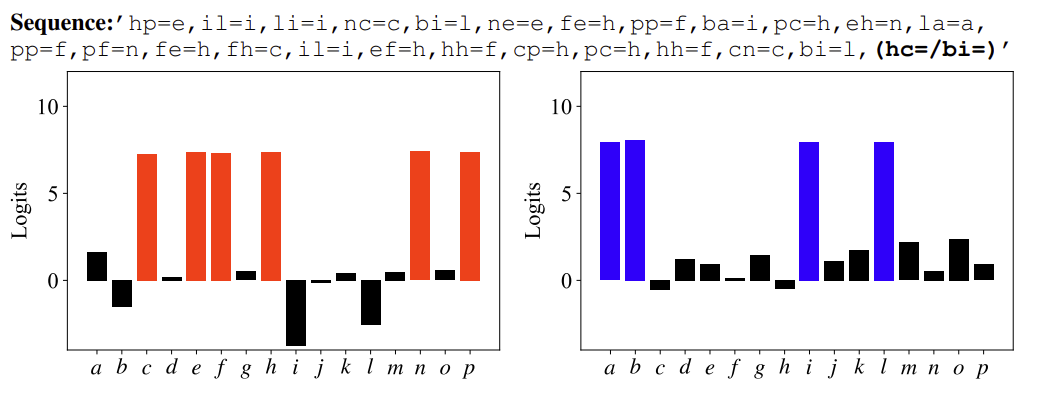
The final mechanism we study is closure-based cancellation. It is also a combination of two complementary sub-mechanisms: (1) tracking and promoting variables belonging to the same group (i.e., the closure), and (2) systematically eliminating invalid answers using the cancellation law. The difference between these two sets produces the final answer. We verify this mechanism by identifying subspaces that causally represent the closure and cancellation sets, due to evidence that this computation is spread across several attention heads.
Phase Transitions Correspond to Learning of Discrete Skills
We find that models undergo a similar sequence of phase transitions during training across different seeds and configurations. Models first learn to (1) predict structural tokens (like '=' and ','), followed quickly by (2) learning to compute group closure: learning that combining two group elements always yields another valid group element. At the same time, the model learns the (3) query promotion submechanism, which can achieve around 50% on identity sequences. The next sharp drop in loss corresponds to the model learning (4) contextual copying, first reproducing facts verbatim and then extending to (5) commutative copying. Once the model can retrieve facts from context, it quickly learns to solve both (6) identity and (7) cancellation facts at the same time. We hypothesize these are learned jointly because the elimination subspace and the identity demotion mechanism perform similar functions, and their "promotion" submechanism counterparts are learned at similar times earlier in training. Finally, models begin to solve some associative sequences. This learning trajectory suggests that models acquire discrete skills in a particular order, building on previously learned mechanisms to learn more complex ones.
Related Work
Our work builds on insights from a growing body of research investigating how transformers learn to perform numeric reasoning tasks, both in small models trained on algorithmic tasks and in large pre-trained language models.
Numeric Reasoning in Small Transformers
 Althea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, Vedant Misra. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. 2022.
Althea Power, Yuri Burda, Harri Edwards, Igor Babuschkin, Vedant Misra. Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets. 2022.
Notes: The first paper to identify and analyze "grokking", where transformers suddenly generalize after extended training. They find model outputs often reflect the structure of the underlying algorithmic task.
 Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, Jacob Steinhardt. Progress Measures for Grokking via Mechanistic Interpretability. 2023.
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, Jacob Steinhardt. Progress Measures for Grokking via Mechanistic Interpretability. 2023.
Notes: The authors reverse-engineer how a one-layer transformer learns to solve modular addition via Fourier token embeddings. They identify three distinct phases of learning where the model first memorizes, then develops generalizing fourier features, then "cleans up" by removing the memorizing solution.
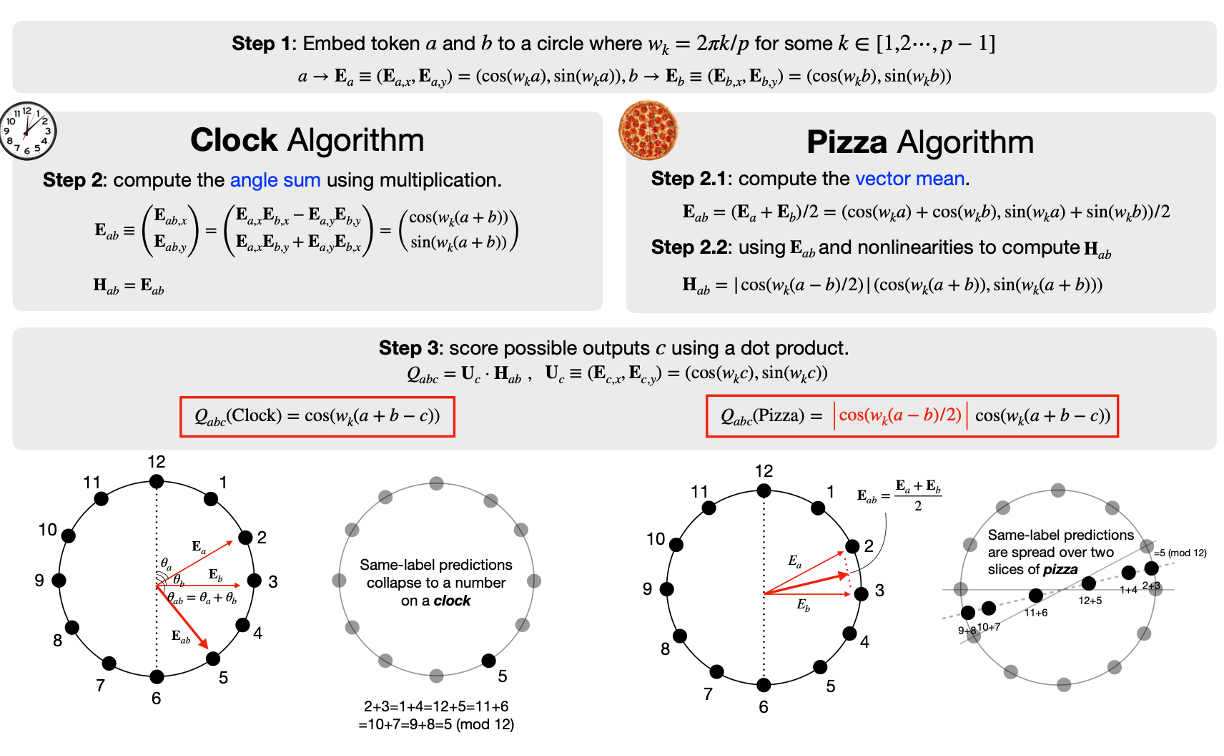 Ziqian Zhong, Ziming Liu, Max Tegmark, Jacob Andreas. The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks. 2023.
Ziqian Zhong, Ziming Liu, Max Tegmark, Jacob Andreas. The Clock and the Pizza: Two Stories in Mechanistic Explanation of Neural Networks. 2023.
Notes: Transformers can learn to solve modular addition by implementing either a "clock" algorithm or a "pizza" algorithm, depending on the random seed used for training. They analyze the mechanisms behind both algorithms, showing both rely on Fourier token embeddings.
 Ziqian Zhong, Jacob Andreas. Algorithmic Capabilities of Random Transformers. 2024.
Ziqian Zhong, Jacob Andreas. Algorithmic Capabilities of Random Transformers. 2024.
Notes: Transformers with trained token embeddings, but otherwise frozen random weights can still implement familiar geometric solutions to solve algorithmic problems, including Fourier token embedddings for modular arithmetic.
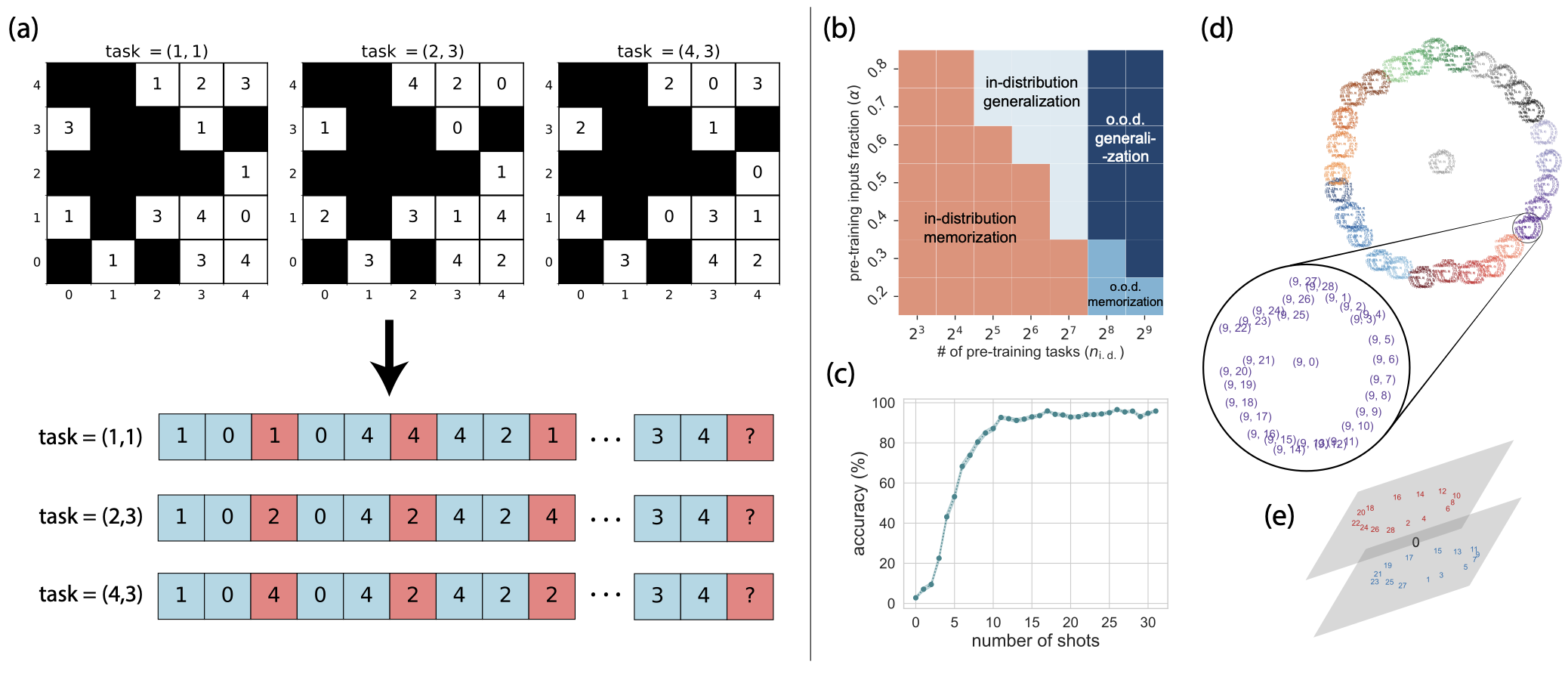 Tianyu He, Darshil Doshi, Aritra Das, Andrey Gromov. Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks. 2024
Tianyu He, Darshil Doshi, Aritra Das, Andrey Gromov. Learning to Grok: Emergence of In-Context Learning and Skill Composition in Modular Arithmetic Tasks. 2024
Notes: This work investigates in-context learning in transformers using modular arithmetic tasks, demonstrating that models transition from memorization to algorithmic generalization (inferring latent task parameters) as the number of tasks shown during pretraining increases.
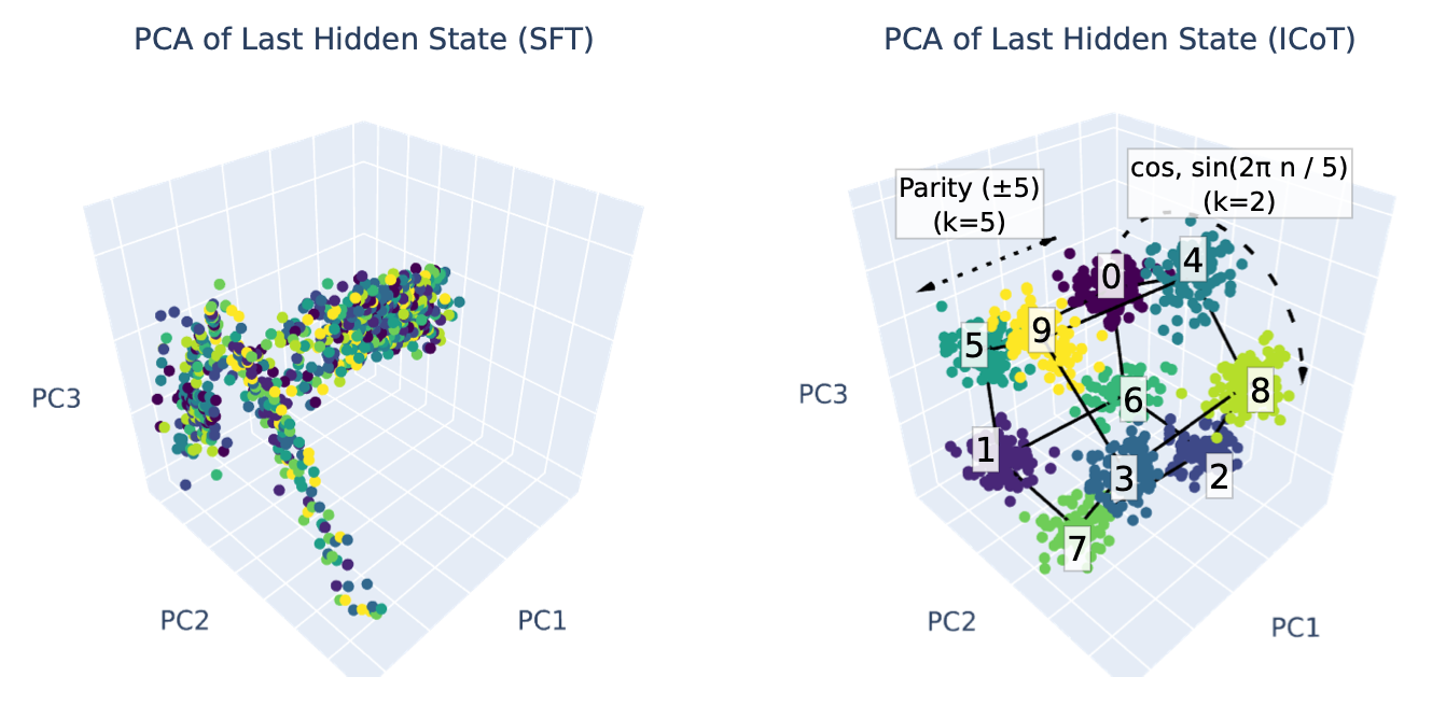 Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viegas, Martin Wattenberg, Andrew Lee. Why Can't Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls. 2025.
Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viegas, Martin Wattenberg, Andrew Lee. Why Can't Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls. 2025.
Notes: Models can learn multiplication via implicit chain-of-thought because they learn to represent numbers using a Fourier basis and represent partial products for long-range computations, while standard fine-tuning does not induce these behaviors and thus fails to solve multiplication.
Numeric Reasoning in Pre-Trained LLMs
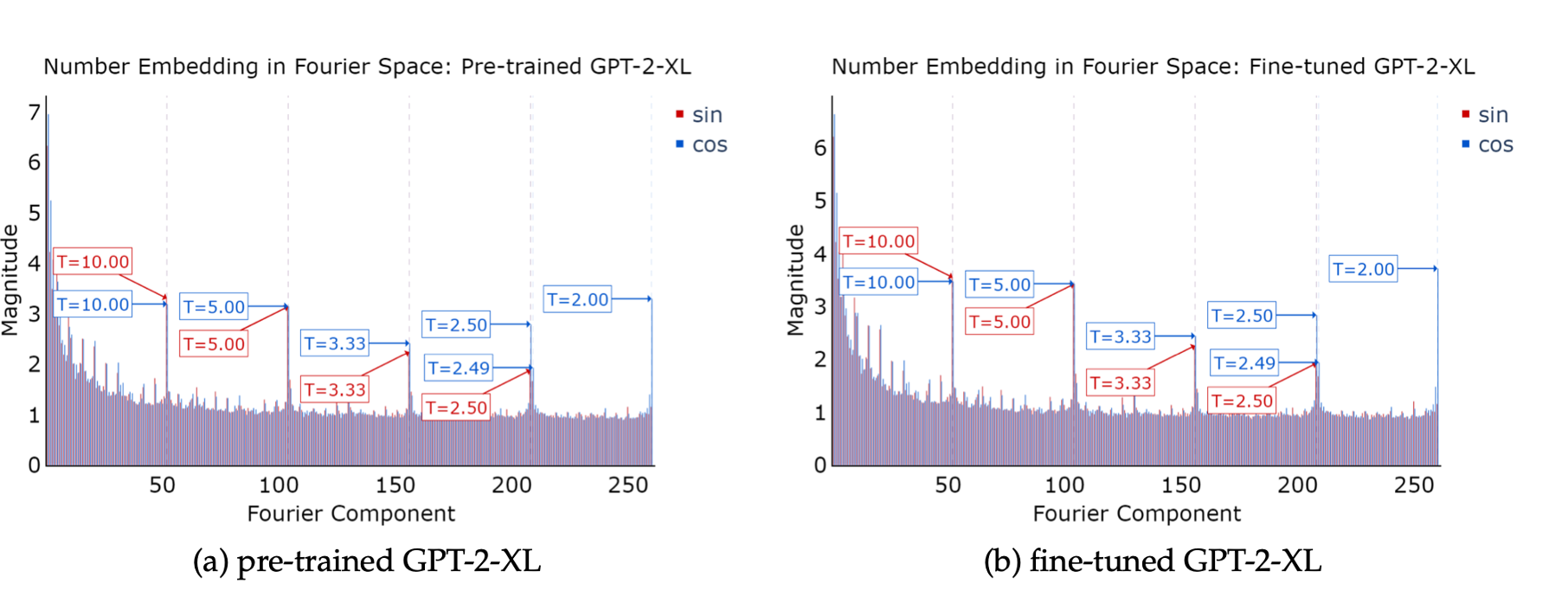 Tianyi Zhou, Deqing Fu, Vatsal Sharan, Robin Jia. Pre-trained Large Language Models Use Fourier Features to Compute Addition. 2024.
Tianyi Zhou, Deqing Fu, Vatsal Sharan, Robin Jia. Pre-trained Large Language Models Use Fourier Features to Compute Addition. 2024.
Notes: Demonstrates that LLMs use Fourier features encoded in their hidden states to solve addition problems. Appropriate pretraining teaches models to better encode Fourier features in number token embeddings.
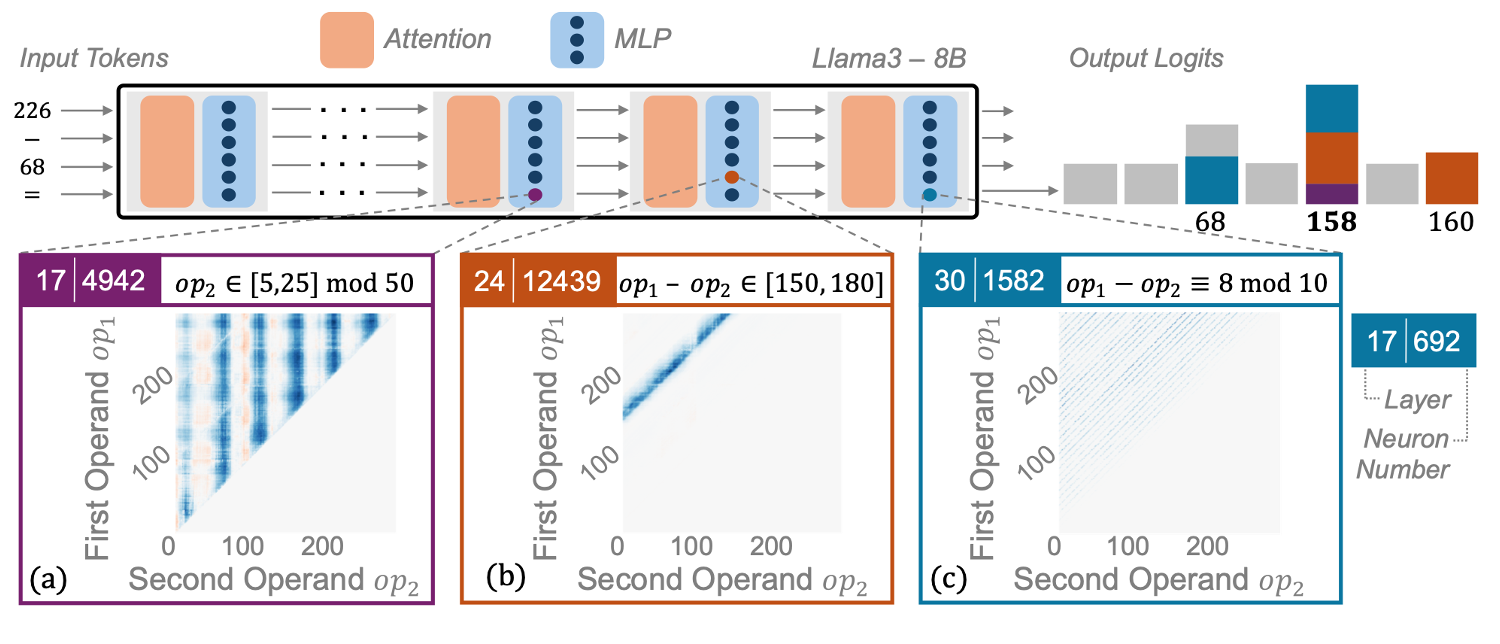 Yaniv Nikankin, Anja Reusch, Aaron Mueller, Yonatan Belinkov. Arithmetic Without Algorithms: Language Models Solve Math with a Bag of Heuristics. 2025.
Yaniv Nikankin, Anja Reusch, Aaron Mueller, Yonatan Belinkov. Arithmetic Without Algorithms: Language Models Solve Math with a Bag of Heuristics. 2025.
Notes: The authors show that pre-trained LLMs use a "bag of heuristics" to solve arithmetic problems. They characterize heuristics that task-specific MLP neurons implement (e.g., number ranges, modulo, and other patterns), which together produce correct arithmetic answers.
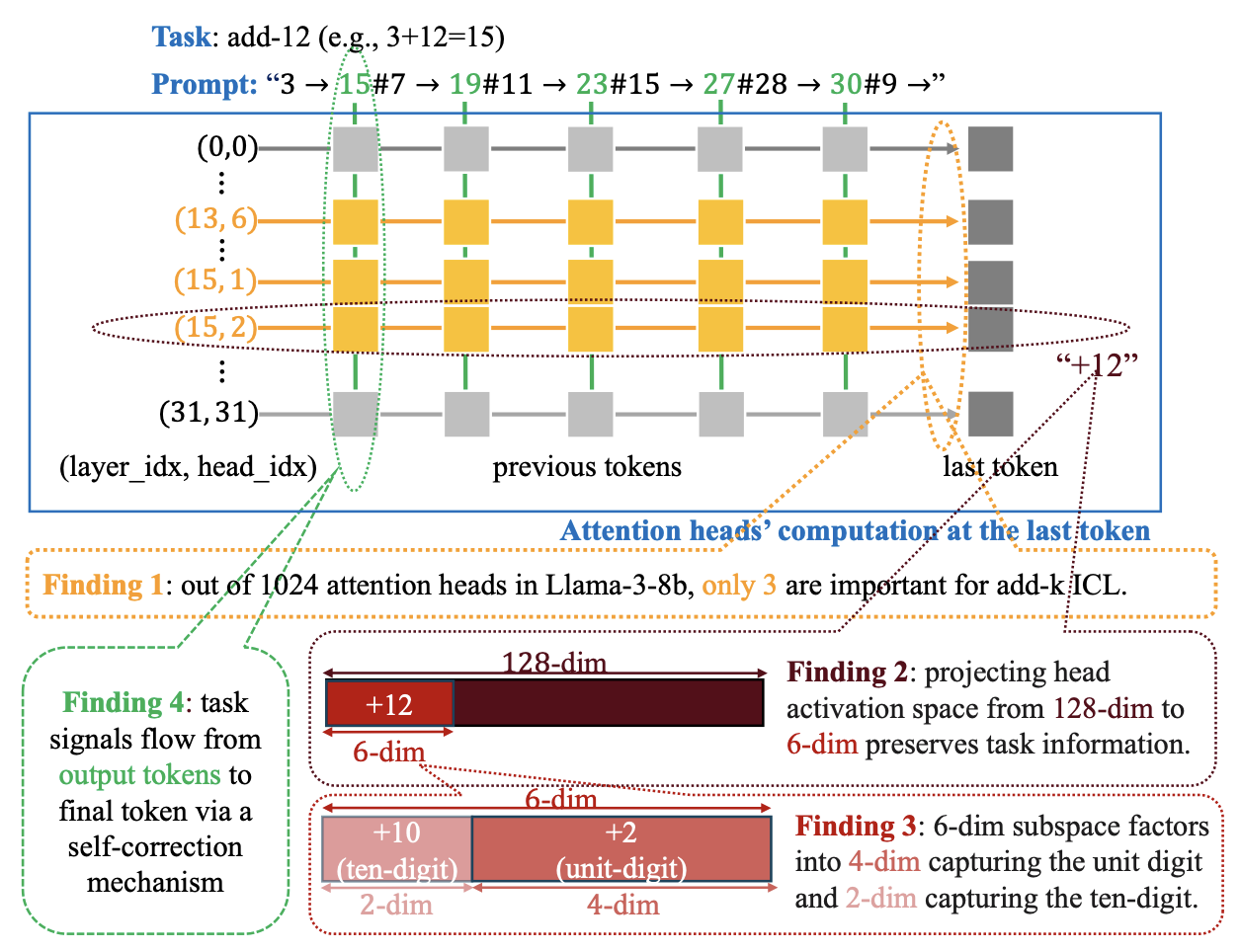 Xinyan Hu, Kayo Yin, Michael I. Jordan, Jacob Steinhardt, Lijie Chen. Understanding In-Context Learning of Addition via Activation Subspaces. 2025.
Xinyan Hu, Kayo Yin, Michael I. Jordan, Jacob Steinhardt, Lijie Chen. Understanding In-Context Learning of Addition via Activation Subspaces. 2025.
Notes: This work studies how LLMs perform addition in-context (add-k), and isolate a low-rank subspace relevant for the task.
They find the dimensions correspond to tracking the unit digit with trigonometric functions at periods of 2,5 and 10, as well as its magnitude.
They identify a self-correction mechanism where later examples suppress errors from earlier demonstrations, improving the prediction.
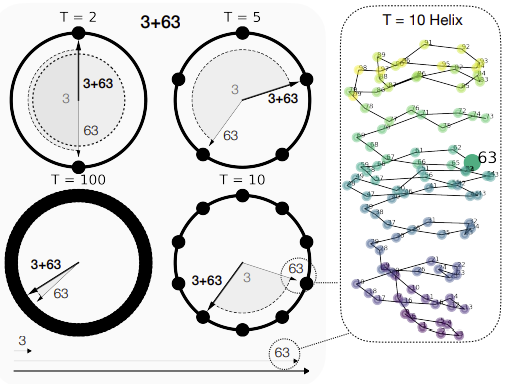 Subhash Kantamneni, Max Tegmark. Language Models Use Trigonometry to do Addition. 2025.
Subhash Kantamneni, Max Tegmark. Language Models Use Trigonometry to do Addition. 2025.
Notes: This paper investigates how LLMs compute addition, and show that pretrained LLMs represent numbers as a generalized helix which is implicated in various computations for mathematical problem solving. The helix can be manipulated using the "clock" algorithm to perform addition.
Variable versus Value Processing in LLMs
 Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. 2025.
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, Mehrdad Farajtabar. GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models. 2025.
Notes: Introduces GSM-symbolic, a variant of GSM8K (Cobbe et al., 2021) that uses symbolic templates to generate a more diverse set of grade school math problems. They find LLM performance has high variance to rephrasings and lacks robustness to changes in numeric values of simple math problems.
 Pedro Calais, Gabriel Franco, Zilu Tang, Themistoklis Nikas, Wagner Meira Jr., Evimaria Terzi, Mark Crovella. Disentangling Text and Math in Word Problems: Evidence for the Bidimensional Structure of Large Language Models' Reasoning. 2025.
Pedro Calais, Gabriel Franco, Zilu Tang, Themistoklis Nikas, Wagner Meira Jr., Evimaria Terzi, Mark Crovella. Disentangling Text and Math in Word Problems: Evidence for the Bidimensional Structure of Large Language Models' Reasoning. 2025.
Notes: The authors investigate word problems by separating text interpretation from equation-solving. They find that small LLMs struggle significantly more with text comprehension than with solving purely expressed math equations.
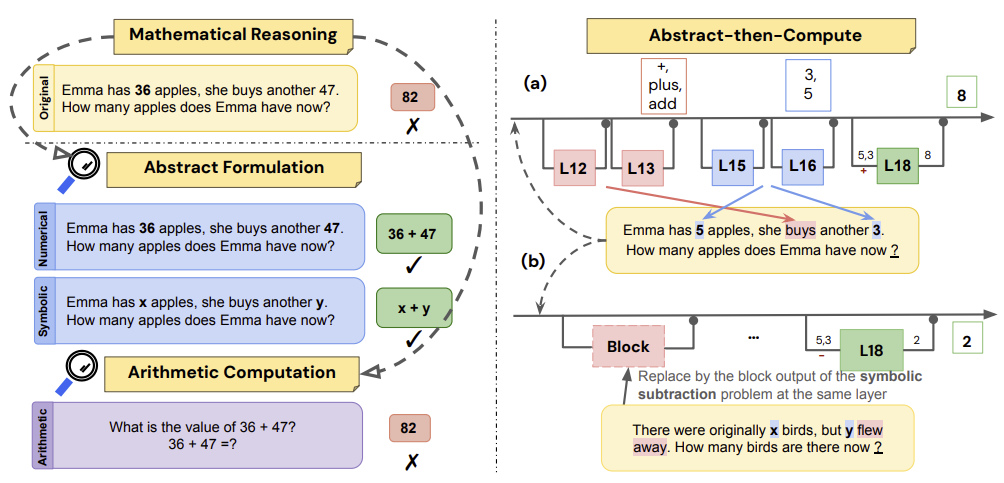 Ziling Cheng, Meng Cao, Leila Pishdad, Yanshuai Cao, Jackie Chi Kit Cheung. Can LLMs Reason Abstractly Over Math Word Problems Without CoT?
Disentangling Abstract Formulation From Arithmetic Computation. 2025.
Ziling Cheng, Meng Cao, Leila Pishdad, Yanshuai Cao, Jackie Chi Kit Cheung. Can LLMs Reason Abstractly Over Math Word Problems Without CoT?
Disentangling Abstract Formulation From Arithmetic Computation. 2025.
Notes: This paper studies abstract formulation versus arithmetic computation in simple word problems (GSM8K). They find LLMs are better at generating variable-based solutions to word problems compared to executing exact arithmetic computations.
How to cite
This work appeared at ICLR 2026. It can be cited as follows.
bibliography
Eric Todd, Jannik Brinkmann, Rohit Gandikota, and David Bau. "In-Context Algebra." The Fourteenth International Conference on Learning Representations (2026).
bibtex
@inproceedings{todd2026incontext,
title={In-Context Algebra},
author={Eric Todd and Jannik Brinkmann and Rohit Gandikota and David Bau},
booktitle={The Fourteenth International Conference on Learning Representations},
year={2026},
url={https://openreview.net/forum?id=J2peqXPQbB}
}